technology · general
Bedrock: a rebuilt coach, polished tracking, and the Engine Room
This is the release that makes Open Water and Moonshot hold together.
Moonshot rebuilt program generation. Bedrock rebuilt the coach around it, polished workout tracking, opened a personalised training library inside the app, and shipped an automated quality judge that scores every program the AI generates. Five groups of work. All closed.
The name picked itself. After the moonshot came the groundwork. Fix the foundations before building more on top. If Moonshot was the rocket, Bedrock is the launch pad.
Here’s what changed and why.
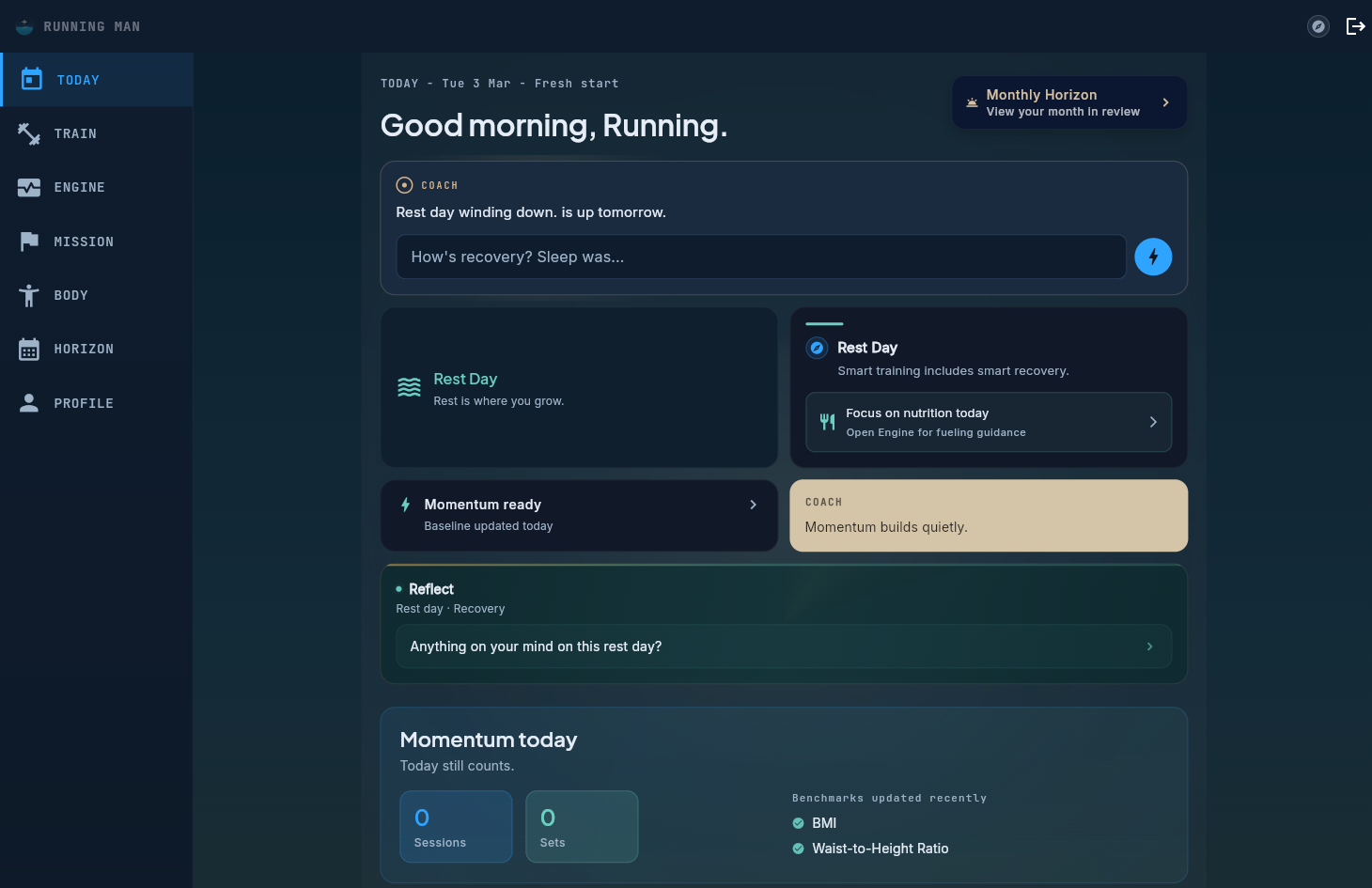 The coach, post-Bedrock. A tool-using agent, not an intent-router pretending to be one.
The coach, post-Bedrock. A tool-using agent, not an intent-router pretending to be one.
A coach that can actually do things
The coach used to sit behind a hand-written intent router. Keyword match on your message to decide whether you were asking a question, logging a workout, or requesting a change. Then route to one of a dozen code paths, each with its own quirks. If the router guessed wrong, the coach got confused. If you asked two things in one message, the router picked one.
Bedrock replaced the entire router with a tool-using AI coach. The AI reads your message, decides which of 14 tools it needs (read session details, log a workout, swap an exercise, update your program, search training resources, and more), calls them in sequence, and stops to confirm with you before writing anything that changes your data. It chains tool calls when the question is layered. “Can you make tomorrow’s session shorter and add a zone 2 run on Thursday?” is one message to one coach, not two separate requests through two separate paths.
Roughly 14,400 lines of old intent-router code left the codebase. About 3,500 lines of cleaner architecture replaced them. The coach pipeline is now a single path, a single contract, and a single place to add capabilities.
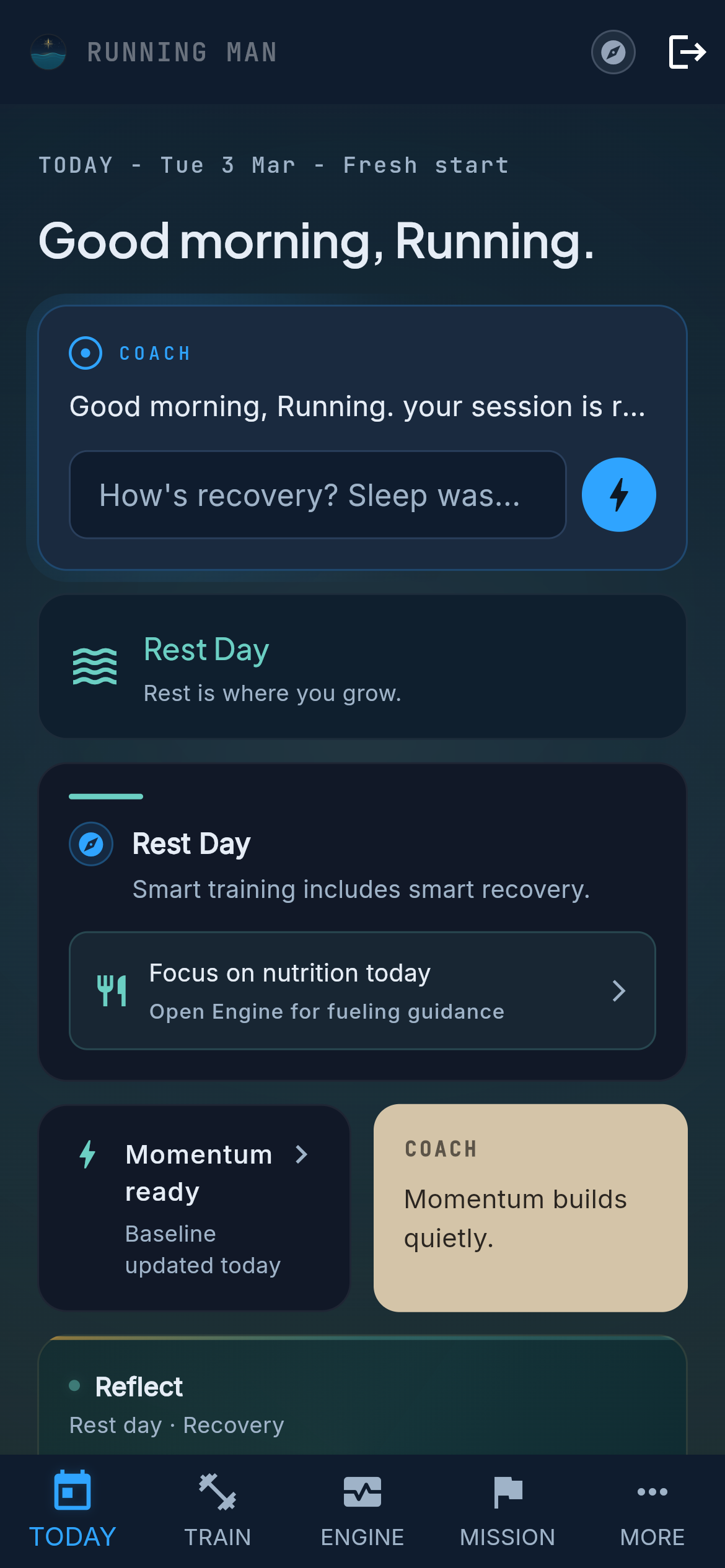 Streaming responses, confirmation gates on writes, and per-tool traces admins can inspect.
Streaming responses, confirmation gates on writes, and per-tool traces admins can inspect.
What you feel: the coach responds faster, handles multi-part asks, remembers context across the conversation, and asks you to confirm anything that would modify your program before it acts. If it’s about to swap an exercise, change your schedule, or log a PR, you see the proposal and accept it. The coach never writes to your data on a guess.
What it unlocks: every new capability we add is a new tool. Nutrition tracking, injury check-ins, race-taper adjustments, two-a-day scheduling, all of these become tools the same coach can reach for, not new screens the coach has to be told about.
Fixing the bugs real users were hitting
Group 1 was the fire-drill work. The bugs that broke real users the moment they started a program.
The Saturday-blocked-day bug. If your program started on any day other than Monday and you had a blocked training day (Saturday for many people), the scheduler could still place sessions on that blocked day. It had been hiding since launch, made visible by a growing number of non-Monday program starts. Fixed at five layers: server prompt, client projection, finaliser validation, JIT scheduler, and session preview widget. Blocked days are now hard constraints everywhere.
Strength Circuit placeholder. Every strength session was being generated with a literal “Strength Circuit” placeholder instead of named exercises. Rewrote the block schema to require a structure plus a populated exercises array, updated the prompt with a worked example, added a validator to catch placeholders and emit replacement operations. Strength sessions now ship with four or more named exercises every time.
Exercise resolver misses. Yoga, Foam Rolling, Calf Raise, Full Body Stretch, these common names were failing the resolver and landing in sessions as unmatched entries. Added canonical aliases for each and tuned the fuzzy-match threshold for compound names.
Coach note routing. MCP-created sessions were rendering the coach’s note as the primary session description. Now it routes to the Coach tab where it belongs, and the session card description stays user-controlled.
Intake drop-off. Our first two real users both finished intake and neither created a program. Dead-end on the Today tab. We now auto-navigate to Training after intake, show a “your program is being built” card while generation runs, and render a clear “create your first program” CTA on Today and Training if the user exits without generating.
Each one small in isolation. Compounded, they were the difference between the app working and the app frustrating.
Workout tracking that respects the basics
The workout tracker is free, and it’s the first thing most people use. That means the basics have to be right.
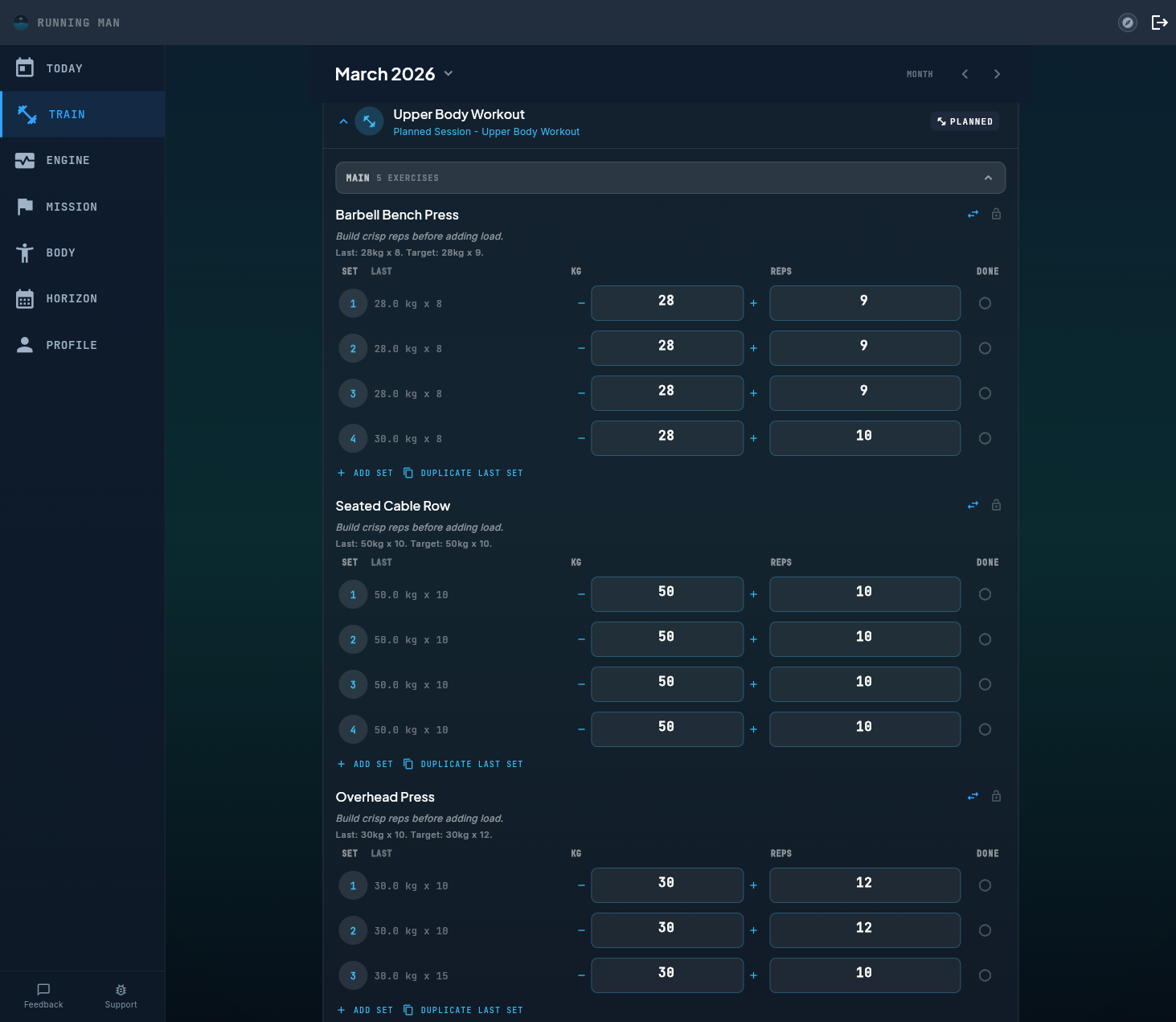 Every set has real targets. Last column populates from exercise_records. PR badges appear on the best set, not the last one.
Every set has real targets. Last column populates from exercise_records. PR badges appear on the best set, not the last one.
Last column, fixed. The “Last” column (previous weight and reps for each exercise) had been unreliable for months because of a name-matching issue with superset prefixes and a server-side write bug that silently dropped exercise_records updates. Rebuilt the pipeline: extended the Firestore schema with lastSessionSets, wired the client getLastBatch to read it, and fixed the root-cause Timestamp.fromDate undefined bug that had been hiding in the diary trigger.
PR detection, fixed. Previously PRs were awarded on the last set of an exercise, which is usually the tired set. Now the algorithm iterates every completed set in the session and checks historical cross-rep dominance. First-time-you-do-an-exercise PRs fire correctly on set 1, not set 3.
Abbreviation search. Typing “DB Bench” now finds “Dumbbell Bench Press” and vice versa. Same for BB, KB. A thin synonym map on top of the search index.
Superset pacing. Rest timer now gates correctly inside a superset or circuit block instead of firing between each exercise. Full intra-superset flow reordering (A1→B1→C1→rest→loop) is partial in this release; the timing is right, the visual reordering is on the next pass.
Manual session create. You can now log any workout, scheduled or completed, from the Training tab. Session-type selector, planned vs completed toggle, exercise picker, save. Uses the same diary service as the AI-generated sessions, so everything shows up on Today and Training like any other session. Table stakes, finally shipped.
Timer panel. Widened to 900px, auto-starts on session start, and the exercise-name cell shrinks before the timer does, so the bit you actually read stays readable on narrow screens.
The Engine Room, a training library that reads your day
The biggest new surface this release is the Engine Room. A personalised training content library inside the app, organised into four categories: fuel, recover, learn, prepare. Same taxonomy as the public guides hub, but ranked per athlete and re-ranked every time you open the tab.
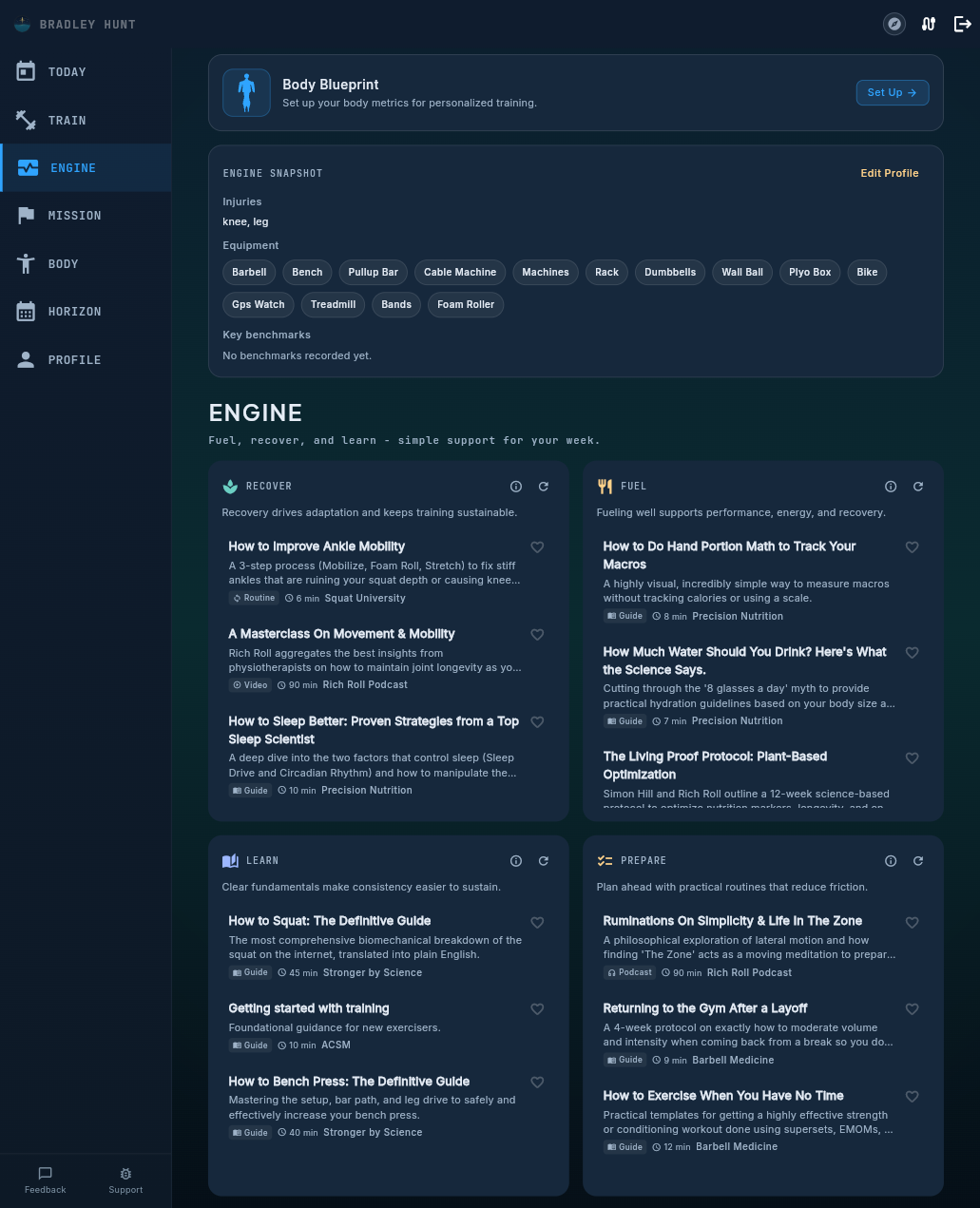 The Engine tab. Four categories, three ranked resources per category, re-ranked for your current program phase.
The Engine tab. Four categories, three ranked resources per category, re-ranked for your current program phase.
The ranking reads six signals: injury match, methodology match, phase match, sport and goal match, context and experience, and equipment. Then applies adjustments for recency (seen in the last 3 days drops; seen 7+ days ago holds; dismissed drops hard for 30 days) and a small boost for new content and favourites.
Marathon base week pulls up aerobic content and long-run fuelling. Marathon peak week swaps in race-day prep. Deload week lifts recovery and mobility to the top. Injury logged? Rehab content climbs. The Engine reads your day and ranks what matters.
138 resources seeded today, curated from peer-reviewed research, professional organisations, established coaches, and twelve first-party Pelaris guides. Growing.
Content on pelaris.io
The public side of Pelaris kept pace. This release grew the marketing and SEO surface substantially.
Sport hubs. Hyrox, CrossFit, and Tennis landing pages, each with real training context, in-app screenshots, and natural cross-links into methodology and the strength and sports hubs.
Endurance hub. A new /endurance page covering open-water swimming, marathon and ultra, multisport, and cycling training. Wired into the Methodology nav. Cross-linked from the five strength endurance sub-pages.
Alternative pages. Hevy, Strong, Fitbod, and JEFIT comparison pages, honest about the tradeoffs, anchored on “tracking is always free, coaching is optional.” Because that is the actual distinction.
Guides library. Twelve guides live at /guides, three per Engine category: deload weeks, sleep for athletes, overtraining signs and recovery, concurrent training, progressive overload, running for lifters, pre-session fuelling, hydration for endurance athletes, protein intake for strength athletes, marathon tapering, in-season team sport training, and returning to training after a break. Each guide answers a real long-tail question and links back into the product where it fits.
Site search. Cmd/Ctrl+K opens search across every page and guide. Built on Pagefind, indexes at build time, zero network call, respects reduced motion.
Security and schema. The site now ships with a full set of security headers (CSP, HSTS preload, X-Frame-Options, Referrer-Policy, Permissions-Policy), a /.well-known/security.txt for responsible disclosure, and enriched Person and Organization structured data that links back to Forbes and IT News for founder authority. Grade went from D to A on securityheaders.com.
Measuring what good looks like
The last piece of Bedrock is the quality judge.
Every program the AI generates now gets scored, after it ships to you, by a second AI model running an 8-criterion rubric. Specificity, progression, modality split, rest adequacy, personalisation, volume, recovery, cohesion. Each criterion is a binary pass or fail, with reasoning recorded.
This is entirely behind the scenes from an athlete’s perspective. The program still lands when it lands, the score is logged afterwards, and your experience does not change. What changes is what we can see. We can now read per-criterion pass rates over 30, 60, 90 days. We can spot regressions in any single criterion after a prompt change. We can drill into any failing program and read exactly what the judge flagged. We can trigger a rescore after a fix to verify it stuck.
This is the instrument we were missing. Without it, program quality was a series of spot-checks by me. With it, it’s a signal we can trend, chart, and chase.
Calibration on three known-bad fixtures comes next, then the inline hook so scores fire at generation time rather than on demand.
The core principle
Bedrock did not change the core principle of the product: if a decision requires understanding, the AI makes it. Code handles execution. The coach rebuild doubled down on that. The Engine ranks on explicit signals because the ranking question is structured execution, not understanding. The quality judge uses AI to evaluate AI, because judging a training program is understanding. Every boundary is deliberate.
If anything, Bedrock made the boundary cleaner. 14,000 lines of intent-routing code made way for a single AI-first path. The tracker’s bugs came from hand-written classification. The Saturday bug came from code quietly overriding what the AI produced. Fix at the boundary.
What’s next
Bedrock stabilises foundations. The next layer is forward-looking work on top: the inline quality hook firing at generation time, multi-select sport in intake, the endurance and hybrid training surfaces deepening with more methodologies, and a coach that keeps accumulating tools as new capabilities ship.
The methodology library is at 40+ science-based systems across 10 sport categories. The guides hub has 12 articles and will keep growing as the Engine’s library does. The workout tracker will always be free.
If you returned to training after a long break, the coach now regenerates a scaled program from your history rather than starting from zero. If you’re tapering for a marathon, the Engine surfaces race-day prep as the date approaches. If you’re juggling strength and endurance, the coach handles the interference effect as a scheduling constraint and lifts relevant guides in the library.
What this means for your training
- The coach responds to intent, not keywords. Ask multi-part questions, request edits, log workouts, all through the same conversation. It confirms anything that writes to your data.
- Your rest days are your rest days. Any start day, any blocked day, sessions respect the boundaries.
- Tracking basics work. Last column populates, PRs fire on the right set, abbreviations find the exercise, supersets pace correctly, you can log anything manually.
- The Engine ranks for your actual day. Marathon base pulls up fuelling. Peak pulls up race prep. Deload pulls up recovery. Injury logged pulls up rehab content.
- Every program gets scored. The quality judge runs on every generation. If something looks off, it’s measured, not guessed.
- Nothing in your history moved. Existing programs, session records, exercise records, and conversations are untouched.
Tracking is free. Coaching is optional. The foundations are bedrock.